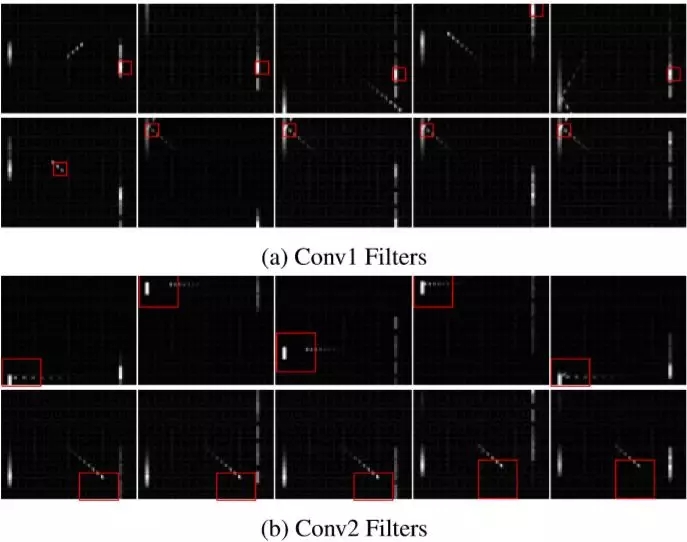
经典 | DRQN神经网络
本文是一篇将强化学习与深度学习结合应用的经典论文,文章来自德克萨斯大学奥斯汀分校,最后一版于2017年修订。DQN神经网络是用于像Atari游戏这样的游戏AI程序,它通过观察游戏屏幕内容,由卷积网络(CNN)捕获屏幕中每一帧的特征来使AI能够“理解”玩游戏的过程,通过强化学习的奖罚机制,让AI成为游戏大师。然而DQN存在一个重要问题:那就是对屏幕捕获的记忆量有限。
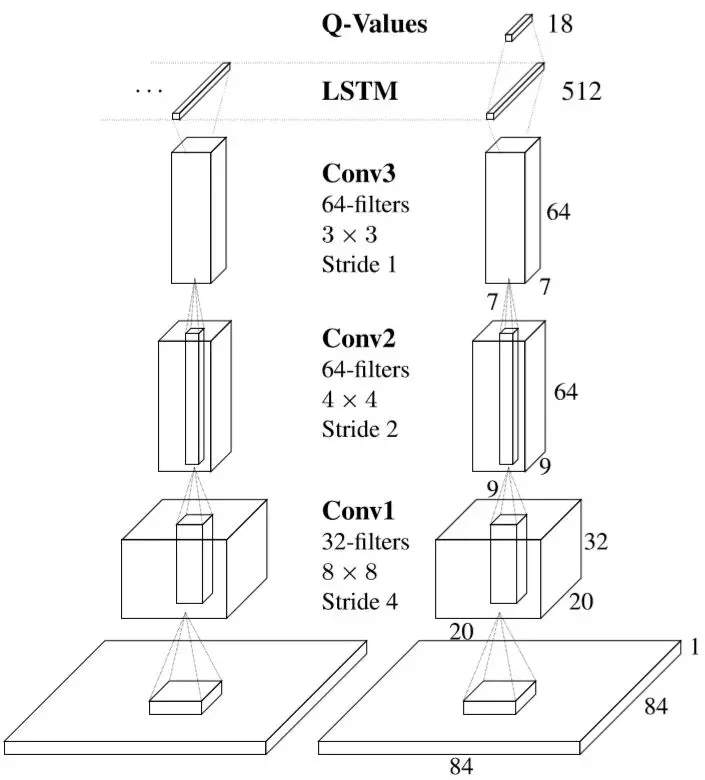
为了解决这样的问题,本文提出的DRQN模型全称为Deep Recurrent Q-Learning Network,即使用RNN中的LSTM等技术来提高DQN的能力。通过用LSTM层替换全连接层来向DQN添加并发性计算的效果。由此产生的DRQN网络虽然能够在每个时间步长只能看到一个帧,但是它可以在时间上成功整合信息,并在标准的Atari游戏中成倍提升性能,其网络结构如下图所示。
网络更新方式
众所周知神经网络是依靠不断迭代更新其参数才能学习更多内容的,最终目标就是让参数跟数据规律达到拟合效果。DRQN网络存在两种更新机制:Bootstrapped Sequential Updates 与Bootstrapped Random Updates。
前者是从观察并记忆到的特征中随机选择剧集(通常称玩一次游戏直至结束为一个剧集,就好象电影一个镜头从开始到导演喊“咔”一样),并在剧集开始时进行更新,直至剧集结束,LSTM隐藏状态被一直保留并不断更新;
后者则是在一个剧集的随机点开始进行更新并直至一次训练迭代结束,LSTM隐藏状态初始值在每次开始更新时被置零(不再保留)。
前者更善于保留信息,而后者更符合随机采样的原则。
旁观者机制(Partial Observability)
马尔可夫决策过程(MDP)是强化学习的核心内容,但是MDP是在假设所有状态在大数定理保障下都可达的前提,例如一个迷宫系统往往并不会复杂到存在那种让人今生今世都走不到的路。但现实情况往往不同,让一个目前科技的AI学习互联网内容可能此生此世都学不完(前提是不更新它),毕竟互联网的生长速度还是难以被超越的。当然通常我们不会涉及到如此复杂的问题,但至少在我们认为恰当的训练时间内有很多现实场景是无法提供所有状态给到AI来进行训练的。
Partially Observable Markov Decision Process(POMDP)就是被提出来更适合于描述现实场景的决策过程方式。MDP使用一个四元组对决策过程进行描述(S, A, P, R),即状态、动作、转换概率与奖励值,而POMDP则使用一个六元组来进行描述(S, A, P, R, Ω, O)。旁观机制由此产生,AI不再通过直接接收系统过程(玩游戏过程)来进行决策计算,而是通过接收一个感兴观察子集o(o ∈ Ω 且 o ∼ O(s))来进行决策。换句话说现在Q网络只需要从部分记忆中提取一些内容来进行学习,而这些提取内容所在的集合称为Ω,并且提取内容的规律符合一个O分布。
总之这篇论文带来的技术就是通过旁观者机制减少数据量、通过LSTM的介入增加并行性能。
比如下面这个玩乒乓球的实例,第一层卷积检测到了球拍,第二层卷积检测到了球的移动,第三层卷积检测到了球与球拍的互动过程,而LSTM的units则能够分别检测到不同的事件:AI跟丢了球、球离开了球拍、球碰撞了墙壁等。