
人工智能|06 踢开Google Net的大门
Google Inception Net v2
第二版本的GooLeNet 论文题目很特殊,主标题为Batch Normalization,这样的题目难免让人匪夷所思,神经网络在哪里?CNN在哪里?但正是这样题外话般的一篇论文,让人们使用至今。在上文中,谷歌创造的网络模型其结构并没有让人感到惊叹,能够留下印象的是对其创造的Inception层的描述。此篇论文则延续了这样的模式,本文主要讲解一种在训练之前进行数据处理的方法,但正是这样的方法废掉了Drop out,让神经网络提前进入稳定阶段,并且使用了类似神经网络训练的方法让这种数据处理层具备了智能。

深度问题
深度学习发展至本文时,已经具有了较大规模的深度,也就是含参网络的层数,当谷歌的工程师对深度网络进行进一步的分析时,发现数据分布对训练结果的影响还是非常大。深度神经网络往往需要很长的训练时间才能够稳定下来,如下图所示,图b为没有添加本文所描述的Batch Normalization层(BN层)时的训练状态,而图c是添加了BN层后的效果,可以看到无论有没有BN,对最后的结果影响都不大,但是对于训练初期,BN层可以起到有效稳定的效果。

根据本文的描述,造成这种抖动的原因是batch,虽然这种数据分批技术能够有效降低过拟合,人们可以通过对数据取小的随机子集来形成batch,但这种数据的子集往往与数据整体的分布不协调。例如某些特征在子集中没有被取到,这样就会导致神经网络训练到这个batch时无法学习这些特征,我们的比赛拥有1000类的数据,如果一个batch取256张图片,则会有大量的图片类型不会在同一个batch中出现,当神经网络深度加深时,逐层提取特征的过程会对图片的具体特征一丢再丢,最终导致神经网络在训练初期出现偏差。
BN算法
当我们谈论到数据分布问题时,最经常看到的一种分布就是高斯分布,即一种钟形曲线。这是最接近于大自然的一种曲线,很多神经网络的训练过程需要加入噪音,而最经常使用的随机噪音就是高斯噪音。在高斯分布中我们需要定义分布曲线的中心点(均值)与辐散程度(方差),而本文就在BN层处理算法中,首先计算这两项值,然后通过下方的公式计算出新的数据输入,最后使用两个自由参数γ与β让BN层变为可训练层,随神经网络动态变化。

整个BN层算法过程如下图所示:

BN层的训练过程与神经网络相似,即有正向传播过程也有反向传播过程。下面的两张图就分别描述了BN层的梯度计算过程与使用BN层的整个神经网络的计算过程。


BN层优势
让我们来罗列一下使用BN层后有哪些好处:
- 由于初期训练更加稳定,就可以快速度过初期欠拟合过程,对于使用学习速率衰减的训练方式,允许在训练开始时使用更高的学习速率;
- 移除了Drop out的技术需求:Drop out是选择性丢弃信息,而BN则是让信息分布更加平均(相对于整个数据来说),所以目前来看BN更加高级;
- 降低了L2惩罚:Inception v1 及很多神经网络模型中,都会使用L2误差惩罚来平衡数据本身对权重更新的影响,这是为了防止过拟合,现在有了BN层,数据更加规范化,可以降低这个惩罚值,毕竟人为设定的参数越少越好;
- 加快学习速率的衰减,数据规范了,就好比高速公路更加通畅了,可以快速降低学习速率以尽早学习更细节的特征;
- 移除了LRN层,LRN最终在这里退出舞台,谁知道之后的模型会不会又想起它呢。
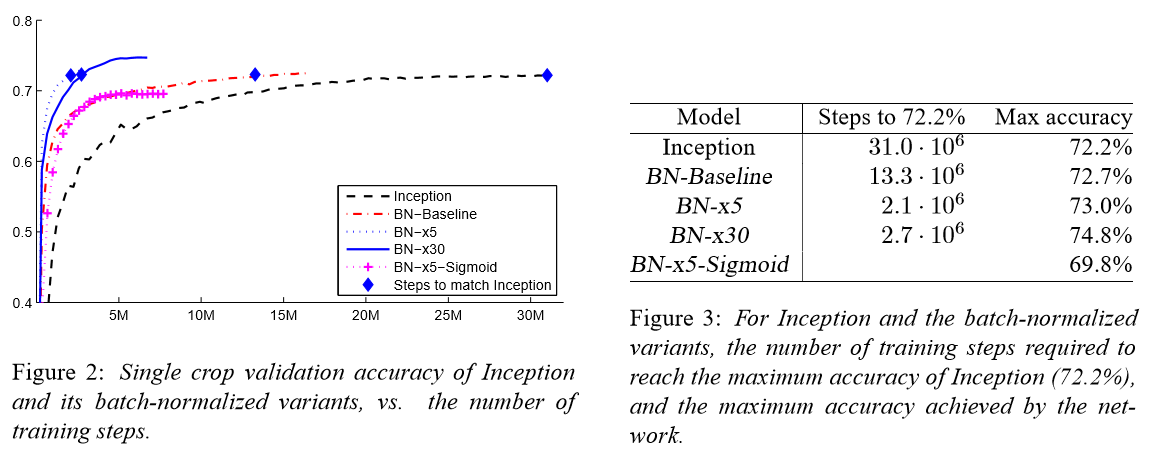
实验结果
最终如上图的描述,Inception v2 超越了其v1版本,并且训练速度更快,或者说主要提高了训练速度。而BN层一直都沿用至今,它的出现让许多人工智能应用看到了希望,甚至为很多终端训练方法提供了思想源泉。想象一下未来的机器人应该需要通过自身“大脑”来训练,而不是每过一段时间就接入数据中心来获取最新“思维”,这样才能做到个性化、多样化,才能与人类共存。

原始论文的下载链接为: https://arxiv.org/abs/1502.03167