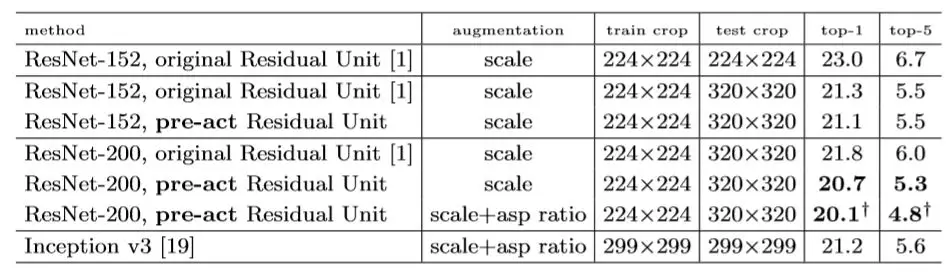
人工智能|09 撸铁撸技术!ResNet_V2
ResNet的第二个版本,论文最终版发表于2016年7月。读完这篇论文,第一感觉就是ResNet V1版本仅仅是作者用来尝鲜,在体验到y=x的无穷魅力后,这个版本将恒等映射的作用发挥到了极致。
首先就是模型中的Block江山易主,V1版本时作者将恒等映射称为“铺路策略”,而在这个版本作者则认为恒等映射才是王道,并且通过不断的研究实验最终证明Block的最后激活使用恒等映射是最佳选择,使用这样的方式来改变ResNet模型,作者在Cifar10数据上建立了1001层深度的ResNet,并将成绩(错误率)降低到了4.92%
作者究竟做了哪些研究呢?首先就是重新推导神经网络的反向传播公式,结果发现反向传播本身是可以推导出能够反映保留信息的形式,即一个来自于较深的层(L)构成的保留信息模式与一个深层与浅层(l)交互表示的模式,梯度为这两者之和。
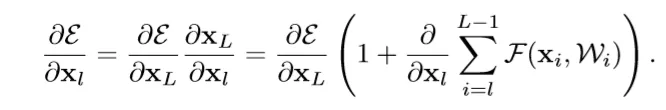
作者进一步在前向传播过程中,为ResNet V1版本的公式添加系数λ后,证明这个系数对于极深的神经网络有极大的影响:如果λ>1则会导致ResNet梯度震荡难以收敛,如果λ<1则会导致ResNet丧失信息保留能力。
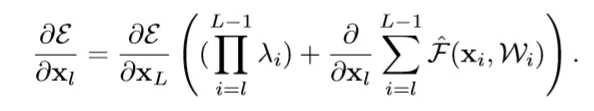
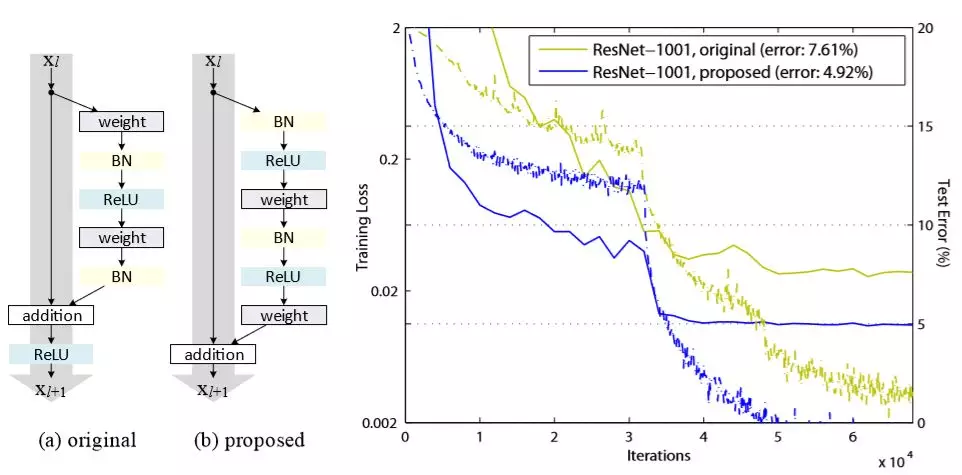
上文都是作者在证明为啥恒等映射那么重要,如果你认为这一次只是把最终激活由ReLU改成恒等映射,那就太简单了。卷积网络模型发展到ResNet已经变成了一种不易修改的模型,重复的结构与动辄过百层的深度确保了你敢动一处就会引发蝴蝶效应。下图描述了作者的研究过程,如果你比较一下第一个模型与最后一个模型,你会发现其配件只是顺序变化而已,数量上还是一致的。从另一个角度讲,对于任何过于复杂的设计,在优化时都应该尽量避免删减。
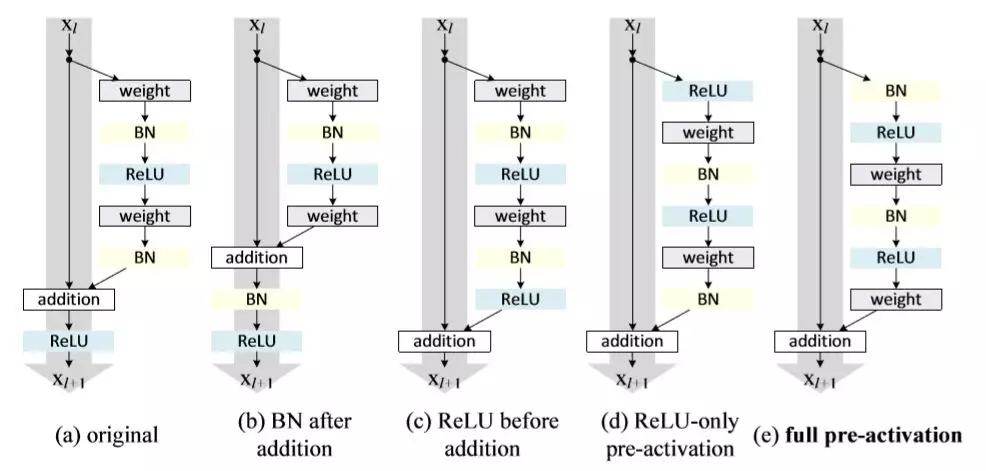
如果大家还是觉得有点迷糊,那么注意a是ResNet V1的结构,而e是本文最终研究成果。并且看下面的分析:
1、 只看右路,即非恒等映射路线,不考虑那个 addition;
2、 a模型顺序:weight -> BN -> ReLU -> weight -> BN -> ReLU;
3、 e模型顺序:BN -> ReLU -> weight -> BN -> ReLU -> weight
作者就像玩“华容道”一样,非常巧妙地将addition移动到了出口,没有删除任何环节,达到了论文中所描述的“预激活”效果。
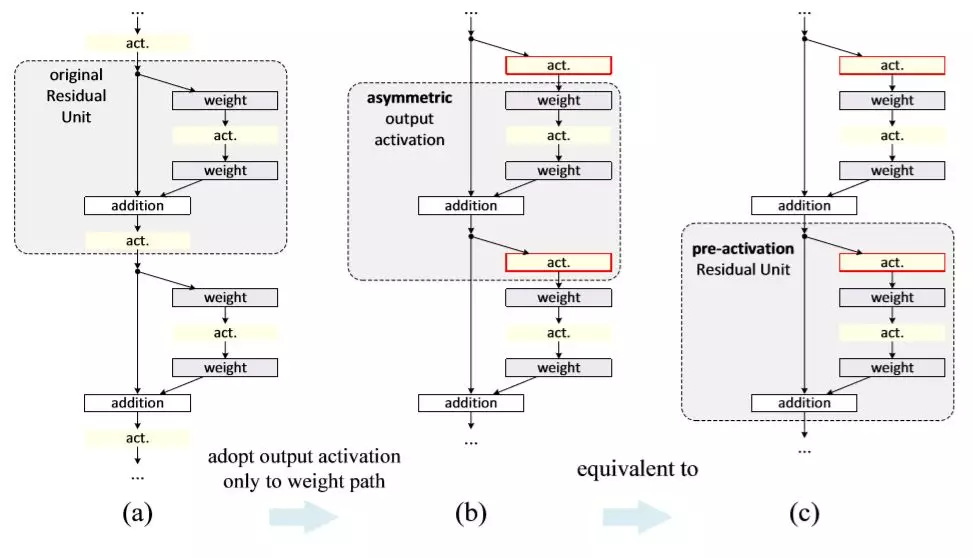
最终这个版本的ResNet在ILSVRC 2012 比赛数据上也获得了超过ResNet V1的效果,如果大家热衷于学习人工智能技术,那最好的方法就是像作者一样将模型翻来覆去地进行调整测试,任何真知一定是源于反复实践才最终获得的。