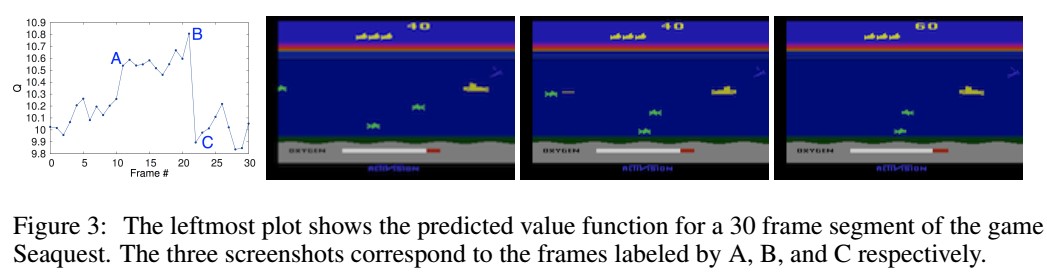
人工智能强化学习02|强化学习的历史
强化学习(RL)的历史
强化学习的早期历史有两条主线,这两条主线冗长而又丰富,在历史长廊中独立成长,直至现代强化学习技术的兴起,它们才开始交织在一起。其中一条主线源于学习理论的心理学部分,即试错学习,这条主线贯穿了人工智能一些早期的成果,并导致了20世纪80年代初强化学习的复兴。另一条主线则涉及使用值函数和动态规划的最优控制问题,大多数情况下,这条主线并不涉及学习理论。两条看似无关的研究线路最终被研究人员混合在一起,并由此衍生了第三条强化学习的研究主线,即时间差分方法。所有三条研究主线在20世纪80年代后期汇集在一起,共同构建了现代强化学习的领域,而这一切的开始可以源于对一种控制系统的最优解决方案。

试错学习(trial and error learning)
试错学习指的是动物在反复过程中完成学习。如小鸟的啄食成功率随年龄而增加。研究者对涡虫、蚯蚓、蚂蚁、蜜蜂、鱼类、鸟类等动物进行试错实验,发现它们均有试错学习行为。要建立这种学习行为,动物必须先有某种欲求动机,对所欲求事物和某种刺激之间建立活动关系,然后发现这种刺激引发的自身活动是无法得到所欲求的事物,在反复尝试的过程中排除错误的活动方式直至成功。Alan Turing在1948年的一份报告中描述了一种“pleasure-pain”学习系统:在某个场景中,当输入给系统的配置所引发的动作,不能达到确定完成目标的效果时,就随机丢弃一些刺激数据,当“痛苦”发生时所有输入被终止,而当“快乐”发生时所有输入被固定在这个场景,这是在人工智能领域最早应用试错学习的例子。但之后就进入了低潮期,很多本应在试错学习上有建树的人都转移到了监督学习上,毕竟监督学习有更易达到的目标。在20世纪60年代,工程学文献首次使用了术语“强化”和“强化学习”来描述试错学习的工程应用(例如Waltz和Fu,1965; Mendel,1966; Fu,1970 ; Mendel和McClaren,1970)。 特别有影响力的是Minsky的论文 《Steps Toward Artificial Intelligence》(Minsky,1961),其中讨论了与试错学习相关的几个问题,包括预测,期望等。

最优控制理论(Optimal Control Theory)
20世纪50年代中期,最优控制理论被提出,它描述了一个受控动力学系统或运动过程,好的设计应该是能够从一类控制方案中寻找最优的那个,使系统的运动在指定时间状态范围内获得最优性能,减少随机行为(不受控行为)。例如对于长跑运动员,如何确定在马拉松比赛过程中体力的分配,使平均速度最快,获得最好的名次。显然这样的问题往往是有数不清的解,而有一个人创造了提出了一种方法,为最优控制问题的解决方案奠定了基础——Richard Bellman。

动态规划(Dynamic Programming Bellman 1957a)
Richard Bellman,1920年8月26日生于美国纽约,1984年3月19日逝世,动态规划的创造者。使用动力系统状态、价值函数以及最优回归函数来定义一个函数方程(贝尔曼方程),通过对个方程求最优解,来实现最优控制问题数学表达的方法被称为动态规划。虽然当时这种方法被Bellman自己称为“受维度诅咒的方法”,意指它的计算量随状态的增加呈现指数级增长。1957年Bellman提出动态规划时,即用来求解最优控制问题中的马尔可夫决策过程。

马尔可夫决策过程(MDPs,Bellman 1957b)
马尔可夫决策过程是最优控制问题的离散随机版本,Ronald Howard(1960)为MDP设计了策略迭代方法。通常人们认为这种“最优控制”过程实际上属于强化学习过程,特别是随机行为的最优控制问题,所以动态规划技术也是一种强化学习技术,毕竟动态规划是增量进行的,也是需要迭代的,通过反复的规划尝试寻找最优方案,以上这些就是现在最流行的强化学习技术的理论基础和算法基石。
时间差分学习(Temporal-difference Learning)
时间差分学习方法最早是源于心理学研究中的二阶刺激(secondary reinforcers),例如某个女孩看到商店展示柜有她很喜欢的一条裙子,这条裙子就是一阶刺激,然而买裙子需要花钱,所以买裙子需要的钱就属于二阶刺激,这两种刺激同时对应于“想要买漂亮裙子”这样的欲望,但如果没有一阶刺激直接给予二阶刺激,即并没有遇到心仪的裙子,这个女孩只会把那些钱先存着,这时二阶的“钱”与心理欲望“想要买漂亮裙子”无法联系起来。1954年Minsky首次发现这种心理学也那就或许可以应用在人工智能上。Arthur Samuel (1959)首次提出一种包含时间差分学习原理的的学习方法,并实施在他的跳棋项目中。所谓时间差分学习,意指使用当前奖励与未来估值来共同计算当前状态值的学习方法。当然,在时间差分学习贡献最多的应该是Richard Sutton,他们将时间差分与试错学习两种概念结合起来,发明了一种结构“Actor-Critic”这个结构至今都出现在一些最新的研究论文中。Sutton 1988年的论文将时间差分学习方法确定为一种更具泛化能力的预测学习方法。
后续研究
接下来随着神经网络等人工智能技术的复兴,强化学习也逐渐赢得了研究人员的深度关注:
1992年Watkins 提出Q-learning 算法;
1994年Rummery 提出Saras算法;
1996年Bersekas提出解决随机过程中优化控制的神经动态规划方法;
2006年Kocsis提出了置信上限树算法;
2009年kewis提出反馈控制只适应动态规划算法;
2013年Deepmind 提出使用Deep-Q-Network方法训练Ai玩Atari2600游戏;
2014年silver提出确定性策略梯度(Policy Gradents)算法;
2015年Google-deepmind 提出正式的Deep-Q-Network算法;
2016年Google-deepmind 提出A3C方法。
Deepmind
从流行角度讲,最能体现强化学习价值的,就是2013年Deepmind使用Deep-Q-Network方法训练Ai玩Atari2600游戏,实现了很好的迁移学习价值,即个别游戏上训练的Ai,能够很快学会玩其他并没有专门训练的游戏。
论文下载链接:https://arxiv.org/abs/1312.5602
在论文的Background部分,我们可以清晰看到Q-Learning的技术细节,包含马尔可夫决策过程等基本算法,而最精彩的Deep Reinforcement Learning部分,描述了他们是如何将Ai玩游戏时的录像转换成图片,利用神经网络对Q-Learning过程进行迭代,自动优化最大奖励等值的人们学习的思维方式,后续文章将会逐渐揭秘这些技术。